Do women play less beautiful chess? A rebuttal
I generally try to avoid the Chessbase news site, as experience has demonstrated that reading its articles generally leads to me hitting my own head more than is considered healthy. But this morning I stumbled across what on the surface seemed an incredible article. Azlan Iqbal, a senior lecturer at the Universiti Tenaga Nasional in Malaysia, wrote an article claiming to have found evidence that women play less beautiful chess than men. He recently presented his scientific findings, based on his own advanced computer software, at the reputable International Congress on Interdisciplinary Behavior and Social Science.
Readers will know that I’ve previously weighed in on the “gender in chess” debate (see here, and in a more academic sense here). But I like to keep an open mind about things, especially if they are backed by scientific evidence, and so I made myself a coffee and sat down to dissect the groundbreaking research of “Azlan Iqbal, PhD”, as he himself writes under the title.
Despite my general rule of distrust for anything written by someone who feels the need to write “PhD” after their name, the fact that his paper was accepted at an international conference was heartening, and Iqbal also provided the slides from the conference and the academic paper for reference. The Chessbase article summarized the main findings, which seemed to conclusively demonstrate that women play less aesthetically than men in his exhaustive analysis of Chessbase’s “Big Database 2015”. It seems somehow absurd on the surface that this result could even be measured, let alone whether it has any truth, but I pressed on, eager to see the real analysis. As the coffee slowly made its way into my system, I decided to start with the conference slides and then move on to the more technical scientific article.
The introduction of the presentation starts with the smiling photos of Magnus Carlsen and Mariya Muzychuk, together with their ELO ratings and the comment that “Statistically, a player rated 2882 has an 88% chance of defeating a player rated 2530 in a game.” Of course, every chess rating system only gives the expected score in a game, and says nothing at all about the chances of winning. Not a great start, but an easy mistake to make and so, excuses made, I moved on. The next slide started with the bold statement “Research suggests that men are better at chess than women.” Ugh! As I (and many others) wrote about extensively, this is certainly not the academic consensus. But everyone’s entitled to their own opinion – even though in this case it was hardly framed as one. I quickly moved on, and – ah! – the next slides have actual chess diagrams in them! Iqbal presents a simple example of a famous mate-in-three:

Seen this before? Of course; it’s a beautiful and famous chess puzzle. Unfortunately, Iqbal’s next slide, purporting to show the solution, begins “1.Nxh6+”. This doesn’t exactly inspire confidence. Naturally we can excuse this as a simple double-typo, although the little errors by now were beginning to accrue.
I hastily moved on to the real analysis. Iqbal describes his methodology as follows: He wanted to compare all mate-in-three sequences by men and women in the Chessbase database of games, ranking them with his patented software ‘Chesthetica’ for aestheticism. Now you might immediately be struck by one obvious questions here, as I was. What evidence is there that executed mate-in-threes can reflect general beauty in playing chess? Unfortunately, the only justification given is that three-move mates give the most consistent testing results from his software. The natural follow-up question is then to ask: how do we know Chesthetica is really measuring chess beauty? Ah, but here Iqbal preemptively counters with that often-used and curiously vague ‘get out of jail free’ card: Chesthica has been “experimentally validated”!
Confused? Never fear; now we get to the real data. Of the 6.3 million games in Big Database 2015, Iqbal extracted a sample of 1069 games by women and 115 games by men. Wait, what? Less than 1200 games out of over six million, and only 115 games by men? What’s going on?! There’s nothing in the slides to explain this inconceivably small sample, so I finally delved in to the full academic paper. And that’s when things got strange.
The first incomprehensible feature of the data collection is that Iqbal extracted only the games where White checkmated Black. This shortcut immediately threw out half the sample. The only reason I can possibly think of for this is that he didn’t want to have to modify his Chesthetica software to be able to flip the colours when it analyzed the Black-checkmating-White games – although given that Iqbal’s profession is computer science, this seems highly unlikely. I honestly have no idea why half the games would be discarded in this way, especially as Iqbal goes on to make the excuse many times in his paper that the analysis suffers from too few suitable games.
But how is it possible that he ended up with fewer male games? Well, the second baffling component is that the sample was split by gender using an incredibly rudimentary method: by filtering for tournaments with “women” or “men” in the game data. And surprise surprise, there were very few men-only events. I have to say that this seems like an astonishingly lazy way to filter the data. Why not just cross-reference the sample against any standard database of female players? Or hey, even just sort manually over a day or two? After all, I guess this is what Iqbal next had to do anyway, because he goes on to write that his team “managed to identify enough additional games between males to bring the 115 set to 1,069 as well.”
I found the term ‘managed’ a bit comical, seeing as he would have had literally tens of thousands of candidate games to choose from. How did they select the games? Were they random? And why limit this to exactly 1,069? Any basic statistical comparison can handle uneven numbers in the samples, and practically always in science, ‘more data is better’ from an academic perspective. It it very strange to say the least to limit one’s sample to an identical match (and highly unlikely that this came about by chance).
The eagle-eyed observer, however, will have noticed an even stranger term in Iqbal’s last sentence: “between males”. And indeed, closer inspection reveals that the database includes games by males only against other males, and games by females only against other females. Why?! Is Iqbal testing whether women play more beautifully against other women, perhaps as an extension of the famous Maass, d’Ettole and Cadinu paper of 2008? Well, no, and in any case, this would still require a sample of checkmates by women against male players.
I can think of no sensible explanation for this restriction, except that perhaps this was what came out of the primitive “women” and “men” tournament search. The result of this piece of academic lethargy is a bit more serious than just reducing the size of the data sample, as in the above cases. It adds an extra potential bias to the data, which is most likely a serious one given that – as Iqbal himself quotes in the paper – research has shown that women play differently against men than they do against other women.
By now I was on to my second coffee and getting slightly worried: I hadn’t yet reached the main results of the analysis and already the data set was (a) unnecessarily small and (b) most likely corrupt. With more than a degree of trepidation, I turned to the slide with the chief experimental results, and breathed a sigh of relief:
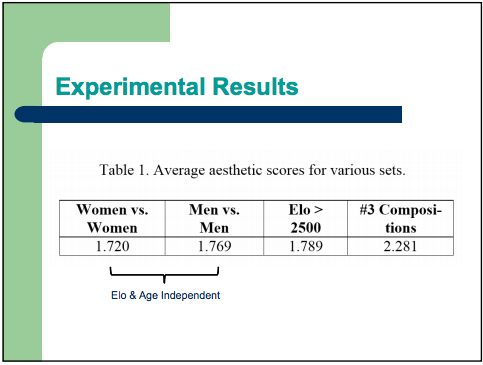
“Elo & Age Independent”! Yes! That was a huge relief to see; after all, the average Elo, a crucial component to aesthetic chess, is most certainly different between the male and female samples, and there’s almost certainly an age difference as well (although how relevant age is to chess beauty is debatable). But the fact that these factors had been excluded was absolutely necessary for the results to have any worth at all.
But I did begin to wonder how Iqbal had done this. After all, it would have required a reasonable (though not infeasible) amount of work to extract these variables from the Chessbase dataset, and all evidence so far had suggested that he was against excessive effort if it could be avoided. I turned back to the academic paper to find out the details. I took a sip of coffee, turned back to the paper, and almost spat it out as I read in black and white:
“There was no filtering based on age or playing strength as this study is concerned more with gender differences and aesthetic quality of play…”
Well.
At this point, I considered whether I should even bother to read the rest of the article. It was of course possible that Iqbal had run multiple econometric regressions to try to control for the influence of age and Elo. But this would have run into all sorts of technical problems, such as the relationships between gender, Elo and age, as well as what we call ‘endogeneity’ – for example, one would have to prove that trying to play ‘beautiful chess’ in all your games doesn’t affect your rating. There are econometric techniques to deal at least in part with many of these concerns. None are mentioned. In fact, the explanation about Elo and age independence is curiously missing entirely from the scientific paper.
Not to worry; we shall persevere! I continued reading. Iqbal’s next result is to show that checkmates by strong players (Elo 2500 and above) are statistically more beautiful than average, according to his software. I doubt this surprises anyone. A major problem with this analysis is that checkmates that actually appear on the board in games are far more likely to occur in much weaker level games. It is very well ingrained chess etiquette for GMs to resign before checkmate is delivered, especially if it is forced (and forced checkmates are the only types Iqbal considers – don’t get me started about this).
So when might a forced checkmate actually be seen in a GM game? You guessed it: when it’s exceptionally beautiful. That’s the only time chess etiquette dictates that a player shouldn’t resign but allow the mate to be played out, if he or she wants. So this means that testing the relationship between Elo and checkmating beauty is inherently, inseparably flawed. GMs allow other GMs to deliver mate only when the checkmates are already beautiful – unless of course it happens during blitz, but no sensible study would include those games.
Well…it turns out Iqbal’s sample does include blitz games. And rapid, and exhibition games, and also – wait for it – games from simultaneous exhibitions.
I could go on, but you are probably already at the limits of your endurance. But allow me to leave you with just a few pearls of wisdom that can be found buried within the discussion in the paper. Iqbal is obviously proud of his main finding that females play less beautifully than males, as he extrapolates this to an insight into the psychological preferences of women, writing:
“Do the results then imply that women have less artistic appreciation of the game? Perhaps.”
He also suggests some keen intuition into the depths of – you’ll like this – the psychology of computers.
“This suggests that computers, regardless of their playing strength or ‘experience’ (if any), …perhaps [have] just no conscious or unconscious appreciation of art…”
All I can say to such shrewd perceptions is: thank God we have men.
It is not all bad news for females. Iqbal does, in a rare concession for the paper, offer the following caveat to his analysis:
“Logically, it would also follow that there are likely domains where women fare better aesthetically than men.”
One or two do come to mind.
Reading over what I’ve written above, I feel a little guilty for the harsh and dismissive way I’ve criticized Iqbal’s work. So let me conclude with a positive note: In general, I am optimistic and supportive of scientific efforts to use chess as a tool to analyze different questions. There have been several interesting academic works in recent years that have done this, and I genuinely think that Iqbal’s Chesthetica software has its role to play in the future of chess research. But such research has to be conducted in a thorough, industrious and attentive manner, especially if it purports to lofty claims in areas such as gender. If not, the methodology is prone to stern aspersion or, even worse, outright dismissal.
I finished my second coffee just as I came to the concluding paragraphs of Iqbal’s paper. And here, finally, I agreed wholeheartedly with one of his generalized statements, and so it’s a good note on which to finish this rebuttal:
“In general, what we have demonstrated should not be taken too seriously…”
With that, I shut down my computer.
I have made a video version of the original article for the benefit of those who are not inclined to read the original, full paper.
https://www.youtube.com/watch?v=dCElBB6zvZs
Hope it helps. By the way, David, I actually have little interest in gender studies but if anyone in that field or related ones would like to send me data of higher quality which they think are more rigorously filtered, I’d be happy to use Chesthetica to assess the data aesthetically for them.
Hi Azlan. Thanks for writing a thorough response. I was sorry to read that some of the comments towards you after your article were nasty and personal. That’s unfair in scientific debates, no matter how touchy the subject matter.
Having said that, your response on Research Gate, coupled with the original paper, reaffirms to me and my academic colleagues that you seem to be lacking some fundamental research skills for this sort of study. While I don’t doubt your abilities in computer science, I think you would really benefit from undertaking a basic graduate course in econometrics, statistical analysis or study design. It’s clear to any researcher in these fields that you’re making some basic academic errors in using your software skills to test hypotheses in an econometric manner. I’d be happy to suggest some sources where could start building up your research skills in these areas, if you decide to go further with this project. I think this will be mandatory if you hope to get this research published in a non-predatory peer reviewed journal.
Regards,
David
My response to the feedback on the article.
https://www.researchgate.net/publication/298819908_Do_Women_Play_More_Beautiful_Chess_A_Response_to_Critics
Well done on your rebuttal. Respect due for the time and effort taken to write that, and the knowledge put into your craft.
Systematically argued, well structured and entertainingly written.
Aside from the hapless research methodology, the crass sexist aspect deserved a beat down, and he got a severe one.
Thanks, and well done.
Brilliant !
Well,
the author probably needs to prove to himself he (as a man) is superior to women at least in the area of chess esthetics. I find that rather outdated way of thinking as this type of article would probably find more success in 19th and early years of 20th century.
But c’mon, gender does not matter here. Women can most definitively play as beautiful chess as we can. It all comes down to one’s oppinion on what’s beauty.
We live in modern age. Men are not superior to women and vice versa. Get used to it Azlan Iqbal!
This wonderful piece of art really reminds me of how much I ‘miss’ Academia. I just glanced through that article and dismissed it as garbage…so thanks David for the reminder AND the effort you put into debunking it 🙂
Unfortunately, it gets more painful than that. Read the Chessbase discussion, but at your peril: http://en.chessbase.com/post/do-women-play-more-beautiful-chess/1#discuss
Author responds:
azlan 48 minutes ago
Thank you for that, Ivan Wijetunge. It brought a smile to my face. Apart from the typo of Nxh6+ in the slides (which I have corrected), I found David’s review to be lacking of any real understanding of my aesthetics model, the scope or constraints of the research. He probably didn’t read the IEEE paper either (perhaps he couldn’t understand it). In any case, he should try getting that review/rebuttal published in an actual academic platform (e.g. conference paper, journal) if he thinks it has other merits apart from the correction of the typo.
An excellent read.
Wow, what a dissection – and deservedly so